1. VITS란?
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech; 종단간 텍스트 음성 변환을 위한 적대적 학습을 통한 변형 추론)는 텍스트에서 음성으로 변환하는 최신 음성 합성 기술 중 하나이다. 이 기술은 변분 추론(Variational Inference)과 적대적 학습(Adversarial Learning)을 결합해 최대한 자연스러운 음성을 만드는 것을 목표로 한다.
그래서 변분 추론이 뭔데?
변분 추론은 복잡한 확률 모델에서 추론 문제를 다루는 방법 중 하나이다. 우리가 관심 있는 어떤 확률 분포를 직접 계산하거나 추론하기 어려울 때, 이를 근사하여 더 간단한 분포를 얻는 방법이라 할 수 있다.
예를 들어, 어떤 겨울배가 일정 이상의 당도를 가지는지에 관련한 확률을 알고 싶지만 그 확률을 직접 계산하기 매우 복잡하다고 하자. 변분 추론은 이 복잡한 계산 대신 다룰 수 있는 더 간단한 형태의 확률 분포를 사용해 그 확률을 근사한다. 물론, 이 과정에서 실제 분포와 근사 분포 사이의 차이를 최소화하는 방향으로 근사 분포를 조정하는 과정이 들어간다.
이를 비유하자면, 매우 복잡한 요리를 해야 한다고 생각해 보자. 이 요리의 정석적인 조리법(실제 확률 분포)을 정확히 따라하는 것은 어렵지만, 비슷한 맛을 낼 수 있는 더 간단한 조리법(근사 분포)을 찾을 수 있을 것이다.
그럼 적대적 학습은 뭔데?
적대적 학습은 GANs(Generative Adversarial Networks; 생성적 적대 신경망)에서 사용하며, 생성기(Generator)와 판별기(Discriminator)가 서로 경쟁하며 학습하는 구조이다.
- 생성기(G): 데이터를 생성하는 역할을 한다. 생성기의 목표는 원본 데이터와 구별이 매우 어려운 수준의 가짜 데이터를 만들어내는 것이 목표다.
- 판별기(D): 생성기에게 받은 데이터가 원본인지 아닌지를 판별하는 역할을 한다. 판별기의 목표는 생성기가 원본 데이터와 매우 흡사한 데이터를 만들어냈다 해도 가짜 데이터라고 할 수 있을 정도로 판별하는 것이 목표다.
생성기와 판별기는 서로를 개선하기 위해 적대적으로 학습한다. 생성기는 판별기를 속이려고 노력하며, 판별기는 더 정확하게 원본과 가짜를 구분하려고 노력한다. 이 과정을 반복하며 생성기는 점점 더 원본과 유사한 데이터를 생성하게 되고, 판별기는 점점 더 정교하게 원본과 가짜를 구분하게 된다.
따라서, 위의 두 기술을 이용해 최대한 원본 데이터(원본 목소리)와 비슷한 데이터(생성한 목소리)를 만들 수 있는 생성기를 만들어 그 생성기에게 텍스트를 전달하고, 이 텍스트를 그대로 말해보라고 함으로써 TTS를 구현할 수 있게 된다.
근데 VITS는 어떤 순서로 동작해?
VITS는 다음과 같은 순서로 동작한다:
- 텍스트 전처리: 입력된 텍스트를 음성 합성을 위해 특정 형식으로 전처리한다.
- 음성 특성 예측: 전처리된 텍스트는 VITS 모델로 입력되어 음성의 특성을 예측한다. 이때, 변분 추론을 사용해 모델의 출력에 다양성을 부여한다.
- 음성 생성: 예측된 음성 특성을 바탕으로 음성 데이터를 생성한다. 이 과정에서 적대적 학습을 사용해 생성된 음성이 실제와 최대한 유사하게 한다.
- 품질 개선: 생성된 음성은 판별기가 판별하게 되고, 이 과정을 통해 VITS 모델이 더 나은 음성을 생성할 수 있게 한다.
- 추론: 생성기에게 텍스트를 주고 음성으로 변환하게끔 하여 음성을 생성한다.
이건 내가 논문 정리본을 읽고 구글 검색을 통해 축약한 정보를 적은 것인데, 이는 매우 알기 어렵고, 딱딱한 문장이다. 더 쉽게 설명하자면 다음과 같다:
- 텍스트를 음성으로 바꾸기: VITS는 입력받은 텍스트를 음성으로 변환하기 시작한다.
- 음성의 조리법 만들기: VITS는 입력된 텍스트를 바탕으로 그 텍스트를 어떻게 음성으로 바꾸면 진짜 음성같을지 고민하면서 레시피를 만든다. 여기서 레시피는 음성의 높낮이, 길이, 강도 등을 어떻게 하면 좋을지 적은 규칙이라 할 수 있다.
- 변화를 주며 실험해보기: VITS는 변분 추론이라는 기술을 사용해 진짜 음성처럼 들리도록 다양한 방식으로 레시피를 조금씩 변형해본다. 마치 우리가 요리를 할 때 조금씩 조미료와 재료를 추가해 맛을 조절하는 것과 비슷하다.
- 진짜같은 음성 만들기: VITS는 적대적 학습을 통해 만들어진 음성이 진짜 음성처럼 들리도록 한다. VITS 프로그램 안에서 생성기와 판별기라는 두 아이가 서로 경쟁하면서 생성기는 최대한 진짜 음성처럼 만들려고 하고, 판별기는 진짜 음성과 구분하려고 한다. 이 과정을 통해 최종적으로 매우 자연스러운 음성을 만들 수 있다.
- 생성기에게 음성을 만들어달라 하기: 잘 훈련된 생성기에게 텍스트를 주고, 이를 음성으로 만들어달라고 한다.
그럼 왜 리포지토리 이름이 VITS가 아니라 VITS-fast-fine-tuning인건데?
그대로 해석하면 빠른 VITS 파인 튜닝인데, 여기서 파인 튜닝이란 이미 학습된 모델을 새로운 데이터셋에 맞게끔 조정하는 과정을 말한다. 처음부터 만들어나가는것이 아니라, 이미 학습된 모델을 조정하는 것이라 빠른 완성 속도를 기대할 수 있고, 훨씬 적은 데이터셋만으로도 좋은 결과물을 낼 수 있다. 그래서 아마 리포지토리 이름을 VITS-fast-fine-tuning이라고 지은 것이라 생각한다.
2. CUDA 환경 및 python 가상환경 구성하기
먼저 알아야 할 것은, 아쉽게도 VITS는 CUDA를 통한 GPGPU 연산밖에 지원하지 않는다. CUDA는 NVIDIA의 GPU에서만 사용할 수 있으므로, NVIDIA GPU가 필요하다.
준비해야할 것은 다음과 같다:
- NVIDIA GPU(단, VRAM ≥ 12GB)
- Ubuntu가 설치된 컴퓨터 (단, RAM ≥ 16GB)
- Git
- pyenv
- Ubuntu용 NVIDIA 드라이버
- CUDA
- cuDNN
- CMake 및 C/C++ 컴파일러
- FFmpeg
NVIDIA GPU 장착 방법과 Ubuntu 설치 방법은 생략한다.
Git
sudo apt update
sudo apt install git
pyenv
- pyenv Github 웹페이지에 접속한다.
- Wiki 페이지로 들어간다.
- Suggested build environment라는 항목를 찾고, 거기서 Ubuntu 항목을 찾는다.
- 적힌 명령어를 그대로 실행한다. 글 작성일 기준 다음과 같다:
sudo apt update; sudo apt install build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev curl \
libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
- 다시 Code 페이지로 돌아온 뒤, 다음 명령어를 실행해 pyenv를 설치한다.
curl https://pyenv.run | bash
- 조금 밑으로 내리면 Set up your shell environment for Pyenv라는 항목이 있는데, 거기서 자신의 쉘 환경에 맞게 명령어를 입력한다.
- 터미널을 닫았다 다시 열고, pyenv 명령어를 입력하여 제대로 작동하는지 확인한다.
Ubuntu용 NVIDIA 드라이버
- NVIDIA 드라이버의 리포지토리를 추가한다.
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
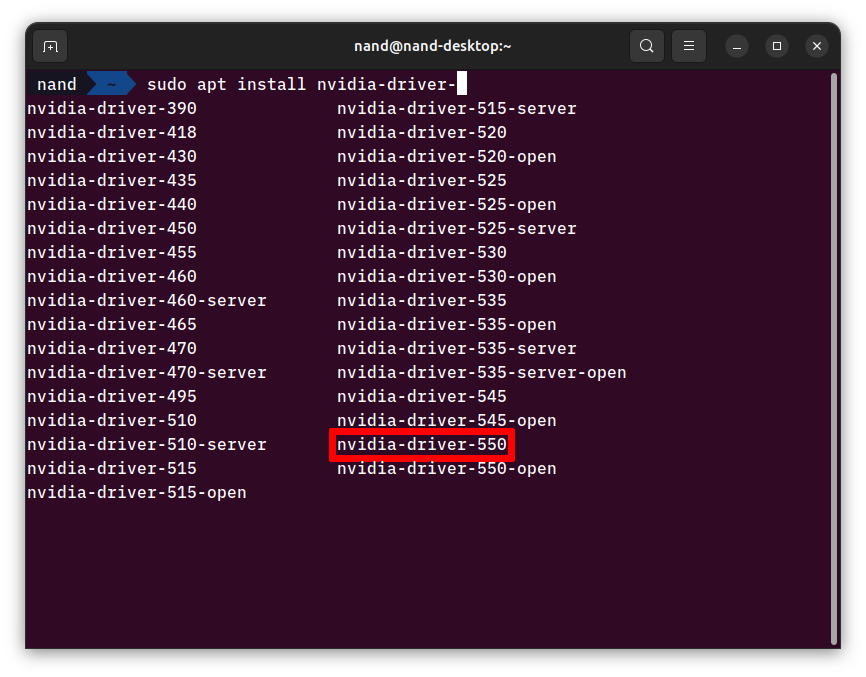
sudo apt install nvidia-driver-까지만 입력한 뒤, Tab키를 눌러 자동 완성 후보로 나오는 NVIDIA 드라이버 중 가장 최신 드라이버를 설치한다.
글 작성일 기준 현재 최신 버전은 nvidia-driver-550이다.- 설치 후, 재부팅을 한다.
nvidia-smi를 입력해 다음과 비슷한 출력이 나오는지 확인한다.
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA TITAN RTX Off | 00000000:28:00.0 On | N/A |
| 41% 33C P8 23W / 280W | 317MiB / 24576MiB | 1% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
CUDA
- PyTorch 설치 설명 사이트에 접속한다.
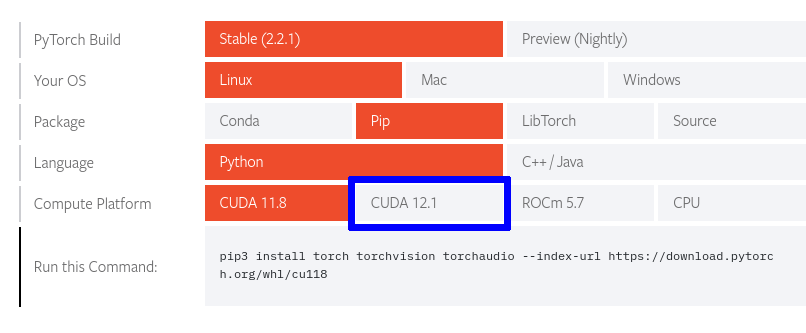
- 'Compute Platform’에서 CUDA 12.x로 된 부분을 보자. 글 작성일 기준 CUDA 12.1인데, 이 12.1이라는 버전을 잘 기억해 두자.
- CUDA 아카이브 사이트에 접속한다. 프로그램 버전은 주(主, Major).부(部, Minor).수(修, Patch) 로 이루어지는데, 예를 들어 방금 본 CUDA 12.1의 경우 주 버전은 12, 부 버전은 1이 된다. 주 버전과 부 버전이 일치하면서, 수 버전이 가장 높은 CUDA 툴킷을 고르자. 나는 CUDA 12.1.1 버전을 선택했다.
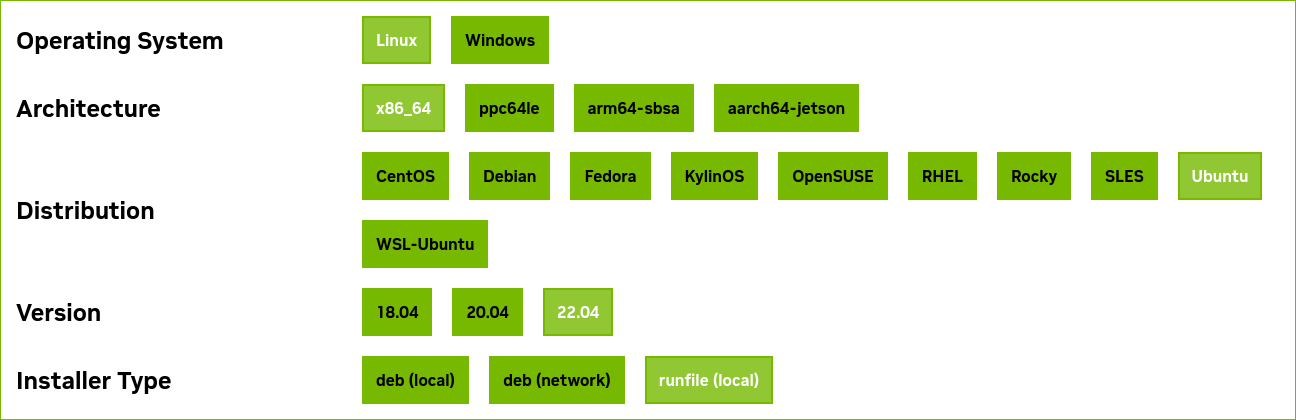
- 운영체제, 아키텍처, 배포판, 버전을 차례대로 알맞게 선택한다. 나의 경우, Ubuntu 22.04 버전용 CUDA 툴킷을 Ubuntu 23.10에 설치했으나, 문제 없이 작동했다. 그러니 버전이 달라도 정상 작동할 것으로 생각된다.
- 설치 종류는 runfile (local)로 선택한다.
- 설치 설명이 나오는데, 설명대로 명령어를 입력한다. 이때, *.run 파일을 실행하기 전에 꼭 --override 인자를 붙여 실행하자. 가끔씩 C 컴파일러인 GCC의 버전이 CUDA의 권장 버전과 맞지 않아 오류가 발생한다.
- 실행했으면, 이미 NVIDIA 드라이버가 설치되었다고 경고하는데, 그대로 진행한다.
- 이제 약관에 동의하고 설치를 하는데, 드라이버는 빼고 설치해야 한다. 방향키를 통해 'Driver’로 이동한 뒤, 스페이스바를 눌러 선택 해제한다. 따라서, 아래와 비슷한 상태가 되어야 한다.
CUDA Installer
- [ ] Driver
[ ] 515.65.01
+ [X] CUDA Toolkit 12.1
[X] CUDA Demo Suite 12.1
[X] CUDA Documentation 12.1
- [ ] Kernel Objects
[ ] nvidia-fs
Options
Install
- 이제 Install로 이동한 뒤, 스페이스바를 눌러 설치한다.
- CUDA가 설치되면, PATH와 LD_LIBRARY_PATH에 특정 환경변수를 추가하라고 할 것이다. bash라면 ~/.bashrc에, zsh라면 ~/.zshrc에 다음 내용을 추가한다. 이때, CUDA의 주 버전과 부 버전에 따라 경로를 수정해줘야 한다. 예를 들어, CUDA 12.3일 경우 아래 명령을 cuda-12.1에서 cuda-12.3으로 바꾸어줘야 한다.
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
- 터미널을 껐다 켠 뒤,
nvcc -V명령을 실행하여 CUDA가 제대로 설치되었는지 확인한다.
cuDNN
- cuDNN 아카이브 웹사이트에 접속한다.
- v8.x 버전 중 가장 최신 버전을 선택한다. 이때, for CUDA 12.x 버전을 선택해야 한다.
- Local Installer for Linux x86_64 (Tar)을 다운로드한다.
- 받은 파일의 압축을 해제한다.
- 압축을 해제한 뒤, cuDNN 디렉토리로 들어가 다음과 같은 명령을 실행한다.
sudo cp include/cudnn* /usr/local/cuda/include
sudo cp lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
CMake 및 C/C++ 컴파일러
sudo apt update
sudo apt install build-essential cmake
FFmpeg
sudo apt update
sudo apt install ffmpeg
3. pyenv 설정하기
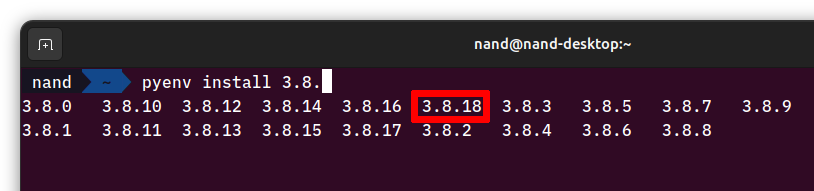
pyenv install 3.8.까지만 입력한 뒤, Tab 키를 눌러 자동 완성 후보를 보고 가장 최신 버전을 선택한다.
글 작성일 기준 가장 최신 버전은 3.8.18이다.pyenv virtualenv {파이썬 버전} {가상환경 이름}으로 가상환경을 생성한다.pyenv activate {가상환경 이름}을 입력한 뒤, 맨 앞에 소괄호와 함께 가상환경 이름이 표시되는지 확인한다.python명령을 실행해 파이썬 버전이 내가 설치한 버전과 맞는지 확인한다.
이제부터는 python 가상 환경에서 모든 작업을 진행한다.
4. 리포지토리 복사 및 VITS 환경 구성
- 먼저 VITS-fast-fine-tuning의 리포지토리를 가져온다.
git clone https://github.com/Plachtaa/VITS-fast-fine-tuning.git && cd VITS-fast-fine-tuning && git reset --hard 96de086509163b8c8aaf5373dffe8fc19b1e5d70
- VITS-fast-fine-tuning 디렉토리로 이동한다.
pip을 이용해 필요 라이브러리를 설치한다.
pip install --upgrade pip
pip install -r requirements.txt
pip install imageio==2.4.1 moviepy
- monotonic align 기능을 Build하고 설치한다.
monotonic align은 텍스트와 음성을 일대일로 정렬하는 과정이다. 간단히 말해서, VITS 모델이 텍스트의 각 부분을 어떻게 발음해야 하는지 정확히 알 수 있도록 도와준다.
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplace
cd ..
- 추가 학습 데이터 다운로드 및 필요한 폴더 생성
mkdir pretrained_models
wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/sampled_audio4ft_v2.zip
unzip sampled_audio4ft_v2.zip
mkdir video_data
mkdir raw_audio
mkdir denoised_audio
mkdir custom_character_voice
mkdir segmented_character_voice
- 파인 튜닝을 할 사전 학습 데이터 다운로드
wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/D_trilingual.pth -O ./pretrained_models/D_0.pth
wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/G_trilingual.pth -O ./pretrained_models/G_0.pth
wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/configs/uma_trilingual.json -O ./configs/finetune_speaker.json
- CJKE(Chinese Japanese Korean Engilsh)를 지원하도록 하기 위해 *.py 파일 바꾸기
원래 이 VITS-fast-fine-tuning은 CJE(Chinese Japanese Engilsh)만 지원하는데, 아카라이브의 에반게리온님이 CJKE를 지원할 수 있도록 수정해 주셨다.
VC_inference.py (6.6 KB)
preprocess_v2.py (6.6 KB)
long_audio_transcribe.py (3.5 KB)
short_audio_transcribe.py (4.9 KB)
- short_audio_transcribe.py와 long_audio_transcribe.py는 scripts 폴더 안에서 덮어쓰기
- preprocess_v2.py와 VC_inference.py는 리포지토리 루트 디렉토리에서 덮어쓰기
- CUDA 및 cuDNN이 PyTorch에서 정상 구동되는지 확인
다음 명령을 python 인터프리터 모드에서 실행한다:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.version.cuda)
print(torch.backends.cudnn.version())
출력된 CUDA 툴킷의 버전과 cuDNN 버전이 내가 설치한 버전과 맞는지 확인한다. 잘 설치된 경우, 다음과 비슷한 출력이 나와야 한다:
>>> import torch
>>> print(torch.__version__)
2.2.1+cu121
>>> print(torch.cuda.is_available())
True
>>> print(torch.version.cuda)
12.1
>>> print(torch.backends.cudnn.version())
8907
5. VITS 학습 데이터셋 생성 및 구동
- 약 20분 단위로 잘린 16bit 모노 44.1KHz wav 파일을 ./raw_audio 폴더에 넣기
이때, wav 파일에는 무음 구간이 거의 없으면서 순수한 목소리만 들어가 있어야 하며, 다른 잡음은 최대한 들어가지 않아야 한다. 그리고, 파일 이름은 다음과 같이 설정한다:
{CharacterName}_{random_number}.wav
- 음성 데이터를 VITS의 데이터셋으로 변환한다. 음성 데이터셋을 잘게 나누고, 음성 데이터들을 텍스트로 변환하는 작업을 거치게 된다.
python scripts/video2audio.py
python scripts/denoise_audio.py
python scripts/long_audio_transcribe.py --languages "CJKE" --whisper_size large
python scripts/short_audio_transcribe.py --languages "CJKE" --whisper_size large
python scripts/resample.py
이때, 다음과 같은 오류가 발생할 경우:
ImportError: Numba needs NumPy 1.22 or greater. Got NumPy 1.21.다음 명령을 실행한다:
pip install -U numpy또한, 다음과 같은 오류가 발생할 경우:
Warning: no short audios found, this IS expected if you have only uploaded long audios, videos or video links. this IS NOT expected if you have uploaded a zip file of short audios. Please check your file structure or make sure your audio language is supported.short_audio_transcribe.py의 61번째 줄을 다음과 같이 바꿔준다:
parent_dir = "./segmented_character_voice/"또한, 다음과 같은 오류가 발생할 경우:
RuntimeError: Given groups=1, weight of size [1280, 128, 3], expected input[1, 80, 3000] to have 128 channels, but got 80 channels insteadshort_audio_transcribe.py 파일을 열고, 19번째 줄을 다음과 같이 바꿔준다:
mel = whisper.log_mel_spectrogram(audio,n_mels = 128).to(model.device)
- 추가 학습 데이터를 사용할 것이므로 다음을 실행한다.
python preprocess_v2.py --add_auxiliary_data True --languages "CJKE"
- 자신이 원하는 에포크(프로그램이 모든 데이터셋을 한번 살펴본 것을 1 에포크라고 한다)를 넣어 학습을 시작한다. 여기서는 10000 에포크를 학습하는 것으로 설정하겠다.
python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs "10000" --drop_speaker_embed True
- TensorBoard로 학습 현황 보기
학습이 제대로 되어가고 있는지 확인하는 것은 매우 중요하다. 리포지토리 루트 디렉토리에서 다음 명령을 실행한 뒤, 출력되는 URL로 접속해 확인한다.
tensorboard --logdir=./OUTPUT_MODEL
- 만약 학습을 도중에 중단하고, 다시 학습을 시키고 싶은 경우 다음 명령을 사용한다.
python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs "10000" --drop_speaker_embed False --cont True
마치며…
이 글에는 VITS와 관련된 간단한 설명과 VITS-fast-fine-tuning 리포지토리를 Clone하여 실행하는 과정을 담았다. 이 글을 통해 TTS와 VITS에 관심을 가지고, 직접 만들어보는 계기를 가져봤으면 좋겠다. 개인적으로 재미있는 경험이었다.